Stateless vs Stateful Browser Automation: A Design Decision

Browser automation fails more often because of state than broken selectors. Authentication tokens expire mid-workflow. Sessions bleed into each other. Cache persists when it shouldn’t. A script that works perfectly in isolation breaks under load.
Most engineers treat state as an implementation detail. It’s not. State is a design decision that determines whether your automation scales reliably or collapses under pressure.
This article explains the difference between stateless and stateful browser automation, why state management is foundational to reliability, and how to design systems that fail predictably instead of mysteriously.
TL;DR
- State is the biggest hidden source of automation failure
- Stateless systems are easier to scale, debug, and secure
- Stateful automation can be faster but is riskier
- Most failures blamed on “flakiness” are actually state leaks
- Reliability starts with making state explicit
What “State” Means in Browser Automation
State is any data that persists between actions or sessions. It’s the memory your automation carries forward sometimes intentionally, often accidentally.
There are four types of state in browser automation:
- Authentication state: Sessions, tokens, cookies that prove identity
- Browser state: DOM snapshots, local storage, cache, service workers
- Workflow state: Where you are in a multi-step process
- System state: Resource allocation, concurrency limits, failure history
State is hard to manage because it’s often invisible. Scripts inherit state from previous runs without explicitly requesting it. Sessions share cookies across workflows. Cache returns stale data that looks valid.
The result: failures that only appear under specific conditions, bugs that vanish when you restart the system, and security vulnerabilities that emerge at scale.
Stateless Automation: What It Is and When It Works
Stateless automation starts fresh every time. Each session runs in a clean browser context with no memory of prior executions.
Core Characteristics:
- New browser instance per task
- No shared cookies or storage
- No assumptions about prior state
- Complete teardown after execution
Advantages:
- Predictable behavior: Every run produces the same result given the same input
- Easier debugging: Failures are reproducible and isolated
- Better security: No session leakage between users or workflows
- Simpler retries: Failed tasks can restart without cleanup
Limitations:
Stateless automation requires repeated setup. If every session needs to log in, navigate through multiple pages, and initialize state, execution slows down. For high-frequency tasks or long workflows, this overhead becomes expensive.
Where Stateless Works Well
- Single-step data extraction
- Read-only scraping
- Low-volume monitoring
- Tasks where security isolation is critical
Stateless-by-default is the safer architecture. It makes failures predictable and scaling straightforward.
Stateful Automation: What It Is and Why It’s Risky
Stateful automation reuses sessions across actions. Browser contexts persist, cookies carry forward, and workflows resume from checkpoints instead of starting over.
Core Characteristics:
- Sessions persist across multiple tasks
- State is explicitly or implicitly shared
- Performance optimized through reuse
- Memory and storage carry forward
Advantages:
- Faster execution: Skip repeated authentication and navigation
- Better UX continuity: Long workflows don’t restart from scratch
- Reduced overhead: Share expensive initialization costs
Risks:
- State leakage: User A sees User B’s data because cookies weren’t cleared
- Non-reproducible failures: Scripts break only after running multiple times
- Security vulnerabilities: Tokens persist beyond their intended scope
- Hidden coupling: One workflow’s failure cascades into another
Stateful automation can be powerful, but it requires explicit boundaries. Without them, state becomes a liability.
The Failure Modes of Poor State Management
Most automation bugs trace back to a mismanaged state. The symptoms are subtle and the root causes are hard to isolate.
Common Failure Patterns:
- Shared cookies corrupting sessions: One workflow logs in as User A, another inherits those credentials and runs as the wrong user
- Stale cache returning incorrect data: A cached response looks valid but represents outdated information
- Zombie sessions holding invalid auth: An expired token persists in memory, causing intermittent authentication failures
- Partial workflows resuming incorrectly: A checkpoint assumes certain state exists, but it was cleared or modified
Why These Failures are Hard to Debug
They’re non-deterministic. The same script succeeds ten times, then fails on the eleventh run. Bugs appear under load but vanish in isolation. Logs capture symptoms but miss the root cause state that shouldn’t have persisted or state that wasn’t initialized correctly.
This is why “it worked yesterday” and “only fails under load” are state problems, not code bugs.
How State Amplifies Failures at Scale
Small state leaks become systemic outages at scale. One corrupted session affects thousands of downstream tasks. State collisions that rarely occur in development become guaranteed under production load.
Concurrency makes hidden coupling visible. When ten workflows run in parallel, implicit state sharing causes race conditions. A session that worked reliably in serial execution breaks when multiple threads access shared memory.
Scaling forces you to manage state explicitly. Systems that ignore state management fail unpredictably as traffic increases.
Designing Stateless-by-Default Systems
Stateless architecture makes reliability easier. Fresh sessions eliminate cross-contamination. Deterministic teardown ensures clean exits. No implicit reuse means no hidden dependencies.
Core Principles:
- Fresh browser per session: Every task starts with a new browser instance
- Explicit initialization: State is never assumed it’s always set explicitly
- Deterministic teardown: Sessions close completely, releasing all resources
- No implicit reuse: Sharing state requires intentional design, not accidental inheritance
Benefits:
- Predictability: Same input produces the same output every time
- Easier retries: Failed tasks restart cleanly without manual cleanup
- Stronger isolation: No cross-session contamination
- Simpler debugging: Failures are reproducible and contained
Stateless-by-default doesn’t mean stateless-always. It means treating state as an explicit design choice, not an accidental byproduct.
When (and How) to Use Stateful Automation Safely
Some workflows require state. Multi-step authenticated sessions can’t restart from scratch every time. Long-running processes need checkpoints. Human-in-the-loop tasks must preserve context.
When State is Necessary:
- Complex workflows spanning multiple pages
- Authenticated sessions with expensive login flows
- Processes requiring human input or approval
- Performance-critical tasks where overhead matters
How to Manage State Safely:
Scope state to a single workflow: Never share state across unrelated tasks
- Enforce TTLs and expiration: State should expire automatically after a defined period
- Version and validate state: Ensure state matches expected structure before use
- Isolate memory and storage: Use separate contexts for different workflows
- Explicit checkpoints: Save state intentionally, not as a side effect
Stateful automation requires discipline. Every piece of shared state is a potential failure point.
State, Isolation, and Reliability
State and isolation are inseparable. Stateless systems make isolation easy; each session is already independent. Stateful systems require stronger boundaries to prevent leakage.
Poor isolation, combined with a shared state, can lead to cascading failures. One corrupted session affects every subsequent task that reuses its context. A single stale token invalidates hundreds of downstream operations.
Reliability starts with how you handle state. Deterministic systems scope state tightly. Retries assume no cleanup. Isolation boundaries prevent cross-contamination.
A System Design Tradeoff, Not a Preference
Choosing between stateless and stateful automation is a tradeoff, not a binary choice.
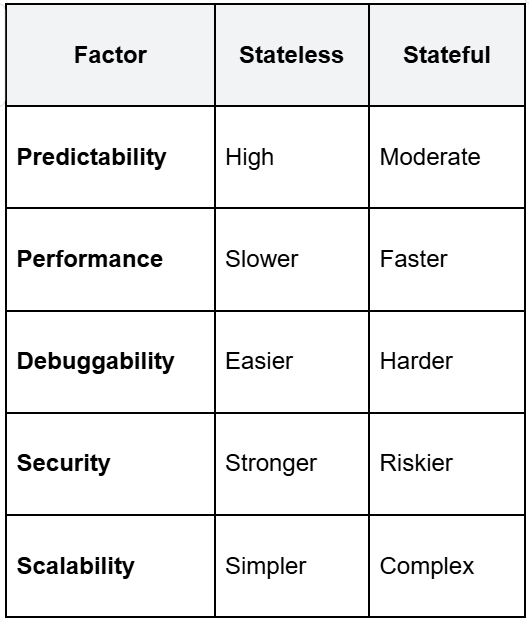
Stateless-by-default scales better and fails more predictably. Stateful automation can be faster but requires careful design to avoid hidden coupling.
The right choice depends on your use case. For most automation, stateless is safer. For performance-critical workflows, stateful can work if you manage state explicitly.
When Browser Automation Fails Because of State
Certain failure patterns signal state problems:
- “It worked yesterday”: Something persisted that shouldn’t have
- “Only fails under load”: Concurrency exposed hidden state sharing
- “User A saw User B’s data”: Sessions leaked across workflows
- “Restarting the worker fixes it”: Accumulated state corrupted the system
These aren’t code bugs. They’re state management failures. Fixing them requires redesigning how the state is scoped, validated, and torn down.
Make State Explicit
State is the silent source of fragility in browser automation. Scripts that ignore state management fail unpredictably. Systems that treat state as an implementation detail collapse under scale.
Design stateless-by-default. Scope state tightly when necessary. Enforce isolation boundaries. Validate state before use.
Reliability starts with how you handle state, not selectors.