Browser Agent vs RPA: Why the Modern Web Demands Adaptive Automation

A browser agent is an AI-native system that executes tasks inside a live web browser by observing the DOM, reasoning about page state, and dynamically adapting to changes.
RPA (Robotic Process Automation): A rules-based software technology that automates repetitive digital tasks by mimicking user interactions through rigid, pre-defined scripts.
While both technologies aim to automate workflows, they represent fundamentally different generations of automation engineering. Browser agents are AI-native systems designed for the dynamic and unpredictable nature of the modern web. RPA tools are legacy, rule-based systems architected for stable, predictable, and unchanging interfaces.
In Simple Terms: Adaptive vs. Recorded
At their core, the distinction lies in how they handle state and intent.
Browser agents are adaptive automation. They function like a human operator who understands the goal (e.g., “book a flight to London”) rather than just the steps. If a button moves or a pop-up appears, the agent perceives the change and adjusts its actions accordingly.
RPA primarily relies on deterministic rules and UI selectors rather than adaptive reasoning. It relies on strict adherence to a script (e.g., “click pixel at X:200 Y:400” or “find element with ID #submit-btn”). It excels in static environments where tomorrow’s interface looks exactly like today’s.
RPA became the enterprise standard because early enterprise software was monolithic and rarely updated. However, the modern web challenges many of RPA’s core assumptions. CI/CD pipelines deploy code daily, A/B tests shift layouts constantly, and dynamic front-end frameworks (React, Vue, Svelte) render DOM elements that defy static selectors.
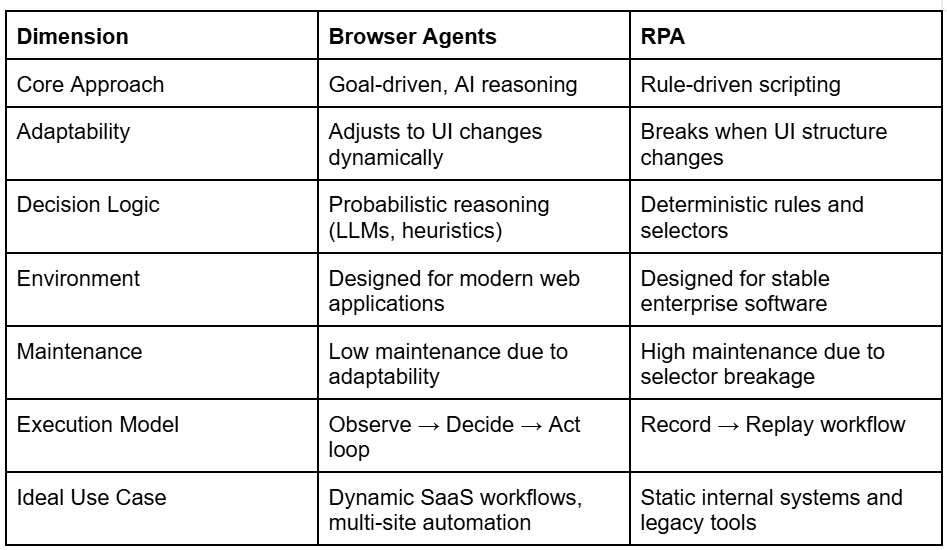
Browser Agents vs RPA: Quick Comparison
The following table summarizes the core architectural and operational differences between browser agents and RPA systems. It highlights how each approach handles adaptability, execution logic, and maintenance in modern environments.
Why This Comparison Matters Now
For senior engineers and architects, the “build vs. buy” or “migrate vs. maintain” decision hinges on a few critical shifts in the landscape:
- Velocity of Change: SaaS platforms update continuously. Hard-coded selectors break instantly when a vendor pushes a UI update.
- Autonomy: We are moving from “attended automation” (where a human watches the bot) to autonomous agents expected to handle edge cases without intervention.
- Maintenance Dominance: In traditional RPA, the cost of maintenance often exceeds the cost of development. Reliability now depends on adaptability, not the precision of the script.
Core Architectural Differences
The divergence begins at the architectural level.
RPA Architecture
RPA is built on deterministic rules. It relies on a “happy path” philosophy where deviations are treated as exceptions to be caught rather than states to be navigated.
- Selectors: Relies on XPaths, CSS selectors, or computer vision anchors.
- Workflow: Linear sequences (If X, then Y).
- Orchestration: Centralized control planes that schedule bots to run on virtual machines.
Browser Agent Architecture
Browser agents run inside a real browser runtime (often headless Chrome/Playwright/Puppeteer) but drive it via a cognitive loop.
- Loop: Observe (DOM/Screenshot) → Decide (LLM/Heuristics) → Act.
- Logic: Probabilistic decision engines capable of understanding semantic meaning (e.g., identifying a “Sign Up” button even if the class name changes from .btn-primary to .btn-blue).
- Session: Ephemeral, isolated sessions that mimic real user behavior, including cookies and local storage handling.
How Execution Differs
When an RPA bot encounters a pop-up ad that wasn’t present during the recording phase, it fails. It cannot find the next element because the pop-up is obscuring it, or the DOM tree has shifted.
A browser agent evaluates the page state holistically. Using a large language model (LLM) or advanced computer vision, it recognizes the pop-up as an obstruction. It reasons that the pop-up must be closed to proceed with the primary goal. It executes the “close” action and then resumes the workflow.
This handling of unexpected states layout shifts, A/B tests, or new validation errors is the defining operational difference.
Adaptability vs. Determinism
In systems engineering, determinism is usually a virtue. We want code to produce the exact same output for the same input. However, when the input environment (the web) is non-deterministic and volatile, rigid determinism becomes a liability.
Browser agents embrace probabilistic reasoning. While this introduces non-zero variance, it paradoxically increases reliability at scale. An agent that is 99% sure it found the right button even though the button moved is infinitely more reliable than a script that is 100% sure the button should be at coordinates 10,10 and fails when it isn’t.
The “hidden tax” of RPA is the rewrite cycle. Every time a target application updates its frontend, the RPA team must:
- Detect the failure.
- Diagnose the broken selector.
- Rewrite the script.
- Redeploy.
Browser agents drastically reduce the Total Cost of Ownership (TCO) by eliminating steps 2 and 3 for the vast majority of UI updates. “Cheap to build” is a trap; “cheap to run” is the goal. Browser agents prioritize the latter.
Observability & Debugging
Debugging a failed RPA run often involves staring at a screenshot of an error message and guessing which step timed out.
Browser agents, by nature of their architecture, offer deeper observability. Because they operate on a “Reasoning Loop,” developers can inspect the thought process of the agent. You don’t just see that it failed; you see why it made the decision it did (e.g., “I attempted to click the ‘Submit’ button, but the button was disabled, so I looked for a missing form field”).
Where RPA Still Makes Sense
RPA remains valuable in environments where interfaces are stable and deterministic. It remains the superior choice for:
- Legacy Internal Systems: Mainframe terminals or desktop applications (Citrix, SAP) that do not run in a browser.
- Static Environments: Processes that haven’t changed in ten years and won’t change in the next ten.
- Highly Regulated Non-Web Tasks: Where probabilistic behavior is strictly forbidden by compliance (though deterministic guardrails can be applied to agents).
Where Browser Agents Clearly Win
For the modern stack, the browser agent is the clear winner:
- Web-Based Workflows: Automating actions across SaaS tools (Salesforce, HubSpot, Jira).
- AI Copilots: Building assistants that browse the web on behalf of a user.
- Cross-Site Automation: Workflows that require navigating multiple domains with different architectures.
- Unstructured UIs: Handling dynamic content feeds or complex, changing forms.
Common Misconceptions
“Browser agents are just smarter RPA.”
This underestimates the architectural shift. RPA is a script; a browser agent is a runtime environment with cognitive capabilities. The difference is akin to a player piano vs. a jazz musician.
“RPA can be made adaptive with enough rules.”
You cannot write enough if/else statements to cover the infinite variability of the modern web. Complexity grows exponentially with rules; it grows linearly with agents.
“AI automation is unreliable.”
Early AI was flaky. Modern LLM-driven agents, when wrapped in proper verification loops (checking if the action had the intended effect), often surpass human reliability in data entry tasks.
Migration Path: RPA → Browser Agents
You do not need to rip and replace everything overnight.
- Identify High-Pain Workflows: Start with the bots that break every week. These are your prime candidates for browser agents.
- Hybrid Approach: Use RPA to trigger browser agents for the web portion of a workflow, then hand control back to RPA for desktop legacy tasks.
- Implement Guardrails: Don’t let the AI guess on critical writes. Use deterministic code for the final “commit” action while using AI for the navigation and data extraction.
Key Takeaways
- RPA is optimized for stability; browser agents are optimized for change. Choose the tool that matches the volatility of your target environment.
- AI-native automation reduces maintenance overhead. The ability to self-heal and adapt to UI shifts is the primary ROI driver.
- Adaptability is now more reliable than rigid rules. In a dynamic web, a flexible agent succeeds where a rigid script fails.
- Browser agents represent the next evolution of automation. They move us from “scripted interactions” to “goal-oriented execution.”
FAQs
Are browser agents compliant?
Yes, provided they are deployed securely. Browser agents can run in ephemeral, sandboxed containers (like Docker) where no data persists after the session. This is often more secure than RPA bots running on persistent VMs.
Do browser agents always use LLMs?
Not necessarily. While LLMs provide the semantic reasoning for complex tasks, many agents use lighter heuristics or computer vision models for speed and cost-efficiency, only calling an LLM when the “happy path” fails.
Can RPA tools integrate with browser agents?
Yes. Most modern automation architectures are composite. An RPA bot can make an API call to a browser agent service to handle a complex web task and return the result.
Is AI automation production-ready today?
Yes. Companies are currently using browser agents at scale for scraping, QA testing, and complex B2B workflow automation. The technology has matured from experimental to operational.