Automation Speed vs. Reliability: Why Faster Often Means Slower

Most teams building automation systems make the same mistake early on: they optimize for speed first. They strip out waits, reduce verification steps, push concurrency to the limit, and cut down workflow length. And for a while, it works. Scripts finish faster. Dashboards look great. Then production happens.
Suddenly there are flaky runs, intermittent failures, inconsistent results, and retry storms that nobody planned for. What looked like a performance win quickly becomes a debugging nightmare.
Here’s the core insight: faster automation is often less reliable. Unreliable automation is usually slower overall. This post breaks down the architectural tradeoffs between speed and reliability-and how to design systems that achieve both.
TL;DR:
- Automation that’s too fast often becomes unreliable, causing more failures and retries.
- Reliable systems may appear slower at first but finish more work, more consistently, at scale.
- Prioritize reliability and observability before optimizing for speed.
- The systems that scale are those where speed is built on a solid foundation of reliability.
What “Speed” Means in Automation
Fast automation typically tries to minimize waiting, skip verification, reuse sessions, run high concurrency, and reduce isolation between tasks. Each of these choices improves raw speed but often at the cost of reliability. Speed isn’t a single metric. Depending on context, it can refer to:
- Execution time per task
- Throughput (tasks per minute)
- Latency (time to first result)
- Infrastructure utilization
What Reliability Means in Automation
Reliable automation is deterministic. It:
- Produces consistent results
- Fails predictably
- Scales without surprises
- Is easy to debug when something goes wrong
To achieve this, reliable systems include verification loops, explicit waiting conditions, isolation boundaries, retry logic, and observability tooling. All of these introduce overhead. Which is exactly why reliable systems often look slower at first glance even when they’re faster where it counts.
Why Faster Automation Often Becomes Slower
This is the core paradox: optimizing for raw speed tends to increase failure rates, which triggers retries, which inflates total runtime.
Consider two systems running the same task at scale:
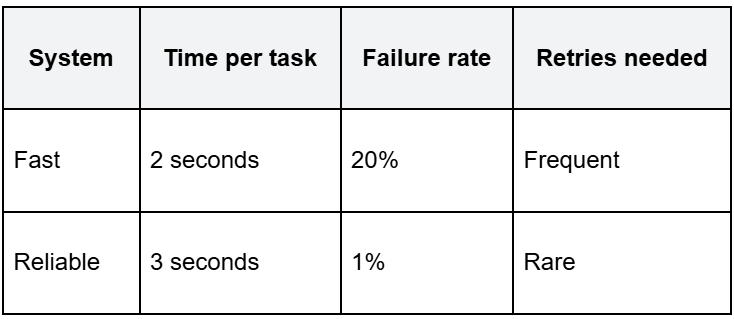
Due to frequent retries, the fast system often takes longer overall. Its effective total runtime can exceed the reliable system as failures accumulate and tasks are re-executed.
At low volume, the fast system wins. However, at scale the reliable system finishes more work in less total time because it isn’t constantly recovering from failures. Speed without reliability creates retry amplification.
The Major Tradeoff Areas
Understanding where speed and reliability pull against each other makes it easier to design systems that balance both.
1. Waiting vs. Racing the UI
Fast automation uses minimal waits and assumes the UI is ready. Reliable automation waits for actionability, checks visibility, and verifies DOM state before proceeding.
Removing waits speeds up the success path but increases race conditions on everything else.
2. Verification vs. Assumption
A fast script clicks and moves on. A reliable script clicks, verifies the state changed, confirms success, and then moves on. Verification adds milliseconds per step. It also prevents silent failures from compounding into larger ones.
3. Stateless Isolation vs. Session Reuse
Fast systems skip login, skip navigation, skip setup by reusing sessions across tasks. Reliable systems prefer fresh sessions and deterministic state for each run. Session reuse improves throughput but introduces hidden coupling between tasks that is difficult to debug.
4. Concurrency vs. Stability
Pushing maximum parallel sessions speeds up aggregate throughput until it doesn’t. Aggressive concurrency causes CPU contention, network throttling, and race conditions. Reliable systems rate-limit concurrency to protect shared resources and isolate failures.
5. Observability vs. Raw Performance
Logs, traces, screenshots, DOM snapshots these add overhead. But they also dramatically reduce mean time to resolution (MTTR) when something breaks. Fast systems often strip out observability to reduce overhead. The tradeoff is paying for that decision every time a failure occurs and nobody knows why.
Why Production Automation Prioritizes Reliability
At scale, failures stop being edge cases. They become operational costs.
A 1% failure rate sounds acceptable. At 100 tasks/day, that’s one failure. At 10,000 tasks/day, that’s 100 failures each requiring investigation, retry logic, and engineering time.
Reliable automation contains those costs through predictable behavior, controlled retry strategies, and clear failure diagnostics. Speed optimizations should come after that foundation is in place.
Where Speed Actually Matters
Speed becomes the right optimization target when:
- Tasks run at extremely high volume
- Workflows are deterministic and well understood
- APIs exist for most operations
- Latency is user-facing and directly impacts the user experience.
In these cases, hybrid architectures are the most effective approach. APIs handle fast, structured operations. Browser automation handles UI-only steps where no API is available. This minimizes browser overhead while keeping workflows reliable.
The Right Optimization Order
Most teams optimize in the wrong sequence:
❌ Maximize speed → add retries → debug flakiness → patch failures
The result is a system that performs well in demos but becomes fragile in production.
The correct sequence:
✅ Build reliability → establish deterministic behavior → add observability → then optimize speed
Reliability first. Speed later. Not because speed doesn’t matter, but because speed built on an unstable foundation rarely lasts.
Designing Systems That Achieve Both
Reliable automation can still be fast. The key is making speed an emergent property of good architecture, not the result of shortcuts.
Deterministic waiting - Wait for events and state changes, not fixed time delays. This removes wasted wait time while preserving correctness.
Hybrid automation - Use APIs wherever possible. Reserve browser automation for UI-only operations. This keeps execution fast where infrastructure supports it.
Safe context reuse - Reuse sessions only within controlled, isolated workflows where state is well-understood. Avoid global reuse.
Smart concurrency - Increase parallelism incrementally. Monitor infrastructure impact. Rate limit before hitting resource ceilings, not after.
Speed should emerge from architecture - not from removing the mechanisms that keep systems stable.
Common Anti-Patterns to Avoid
These are the most frequent speed-first mistakes in production automation:
- Removing waits entirely - causes race conditions that only surface under load
- Disabling verification - allows silent failures to propagate through workflows
- Reusing sessions globally - creates hidden dependencies between unrelated tasks
- Running unbounded concurrency - overloads infrastructure and causes cascading failures
- Ignoring observability - makes failures expensive to diagnose and fix
Each of these produces fast demos. Most produce fragile systems in production.
Reliability vs. Speed in AI Agents
AI browser agents introduce an additional dimension to this tradeoff. Speed-first agents run more reasoning loops, increase retry frequency, and consume more tokens. Reliability-focused agents reduce unnecessary loops, avoid redundant retries, and control token spend by resolving tasks correctly the first time.
In agentic systems, reliability improves both infrastructure cost and token economics simultaneously, making it even more valuable than in traditional automation.
Speed and Reliability Aren’t Opposites But Order Matters
The goal isn’t to choose between a fast system and a reliable one. It’s to build reliability first, then optimize for speed with the confidence that the foundation will hold.
Faster scripts with high failure rates don’t save time. They shift time from execution to debugging. Reliable systems reduce systemic costs, make failures diagnosable, and create the headroom to push performance further.
Build for determinism. Invest in observability. Then tune for speed. The systems that scale are the ones where speed is earned through reliability not shortcuts.